Learning & Planning
Paper Reading
/读CCF A类 期刊/会议/
课题方向:1. 视觉问答+多模态大语言模型
2. 视频时刻定位+组合图像检索一
3. 多模态疾病预测:胸片,放疗血液毒性,医疗问答
论文阅读方向:
医疗视觉问答、胸片报告生成、医疗多模态语言模型、多模态语言模型、多模态幻觉;
【关键词】:medical visual qustion answering、medical report generation、visual language model, multimodal large language model,image captioning,VLM、MLLM;
找论文:
1 | website: |
论文阅读+看源码
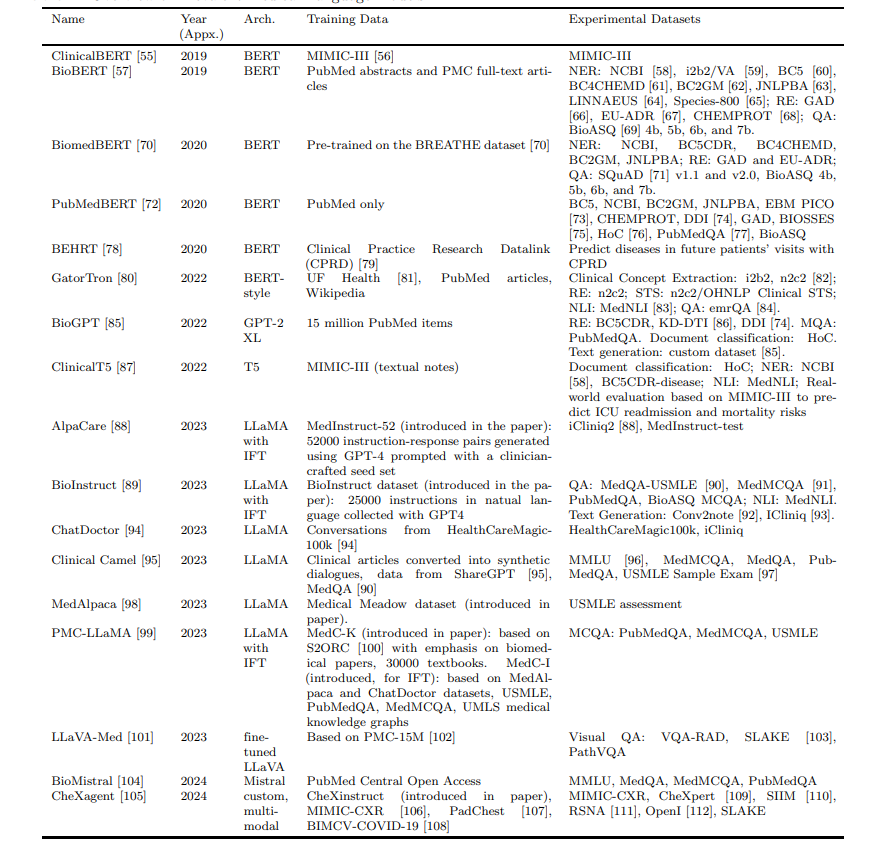
医疗大模型综述:https://arxiv.org/pdf/2408.11735

Skills learned
分布式训练
- 模型并行:模型过大单GPU显存不足无法加载,将模型切割为几个部分分别加载不同GPU
- 数据并行:每个GPU复制一份模型,将一批样本分为多份分发到各个GPU进行计算,相当于加大了batch_size
a. Data Parallel (DP):
1 | 数据并行 |
1 | 并行数据加载 |
流程:
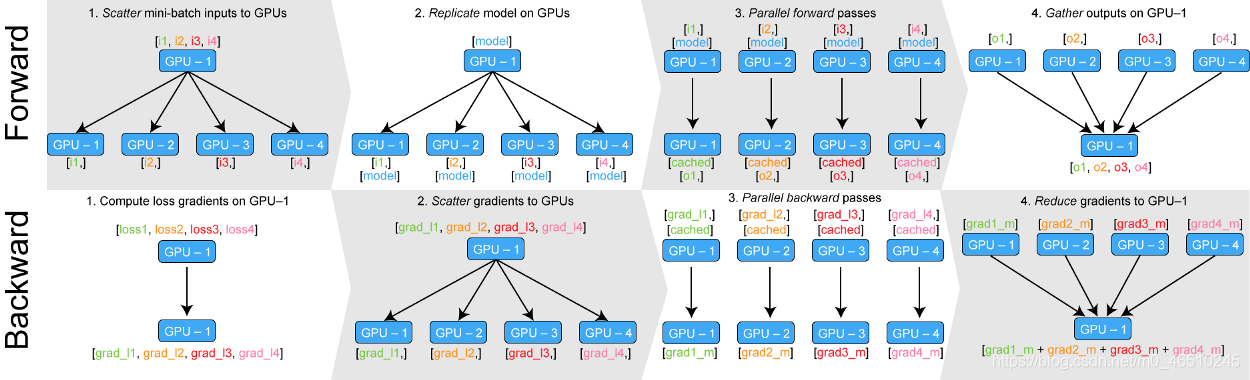
基本上,给定的输入通过在批处理维度中分块在GPU之间进行分配。 在前向传递中,模型在每个设备上复制,每个副本处理批次的一部分。 在向后传递过程中,主GPU(上图中的GPU-1)收集每个GPU的输出output,根据label计算loss,继而计算得到多个梯度grad,然后将梯度分发到各个GPU(官方原理图中第二行第二个),然后每个GPU副本模型上的梯度更新(第二行第三个),然后再将每个更新完梯度的的参数合并到主gpu(第二行最后一个步骤),求和以生成最终的梯度,并将其应用于主gpu(上图中的GPU-1)以更新模型权重。 在下一次迭代中,主GPU上的更新模型将再次复制到每个GPU设备上。
b. Distributed Data Parallel (DDP):
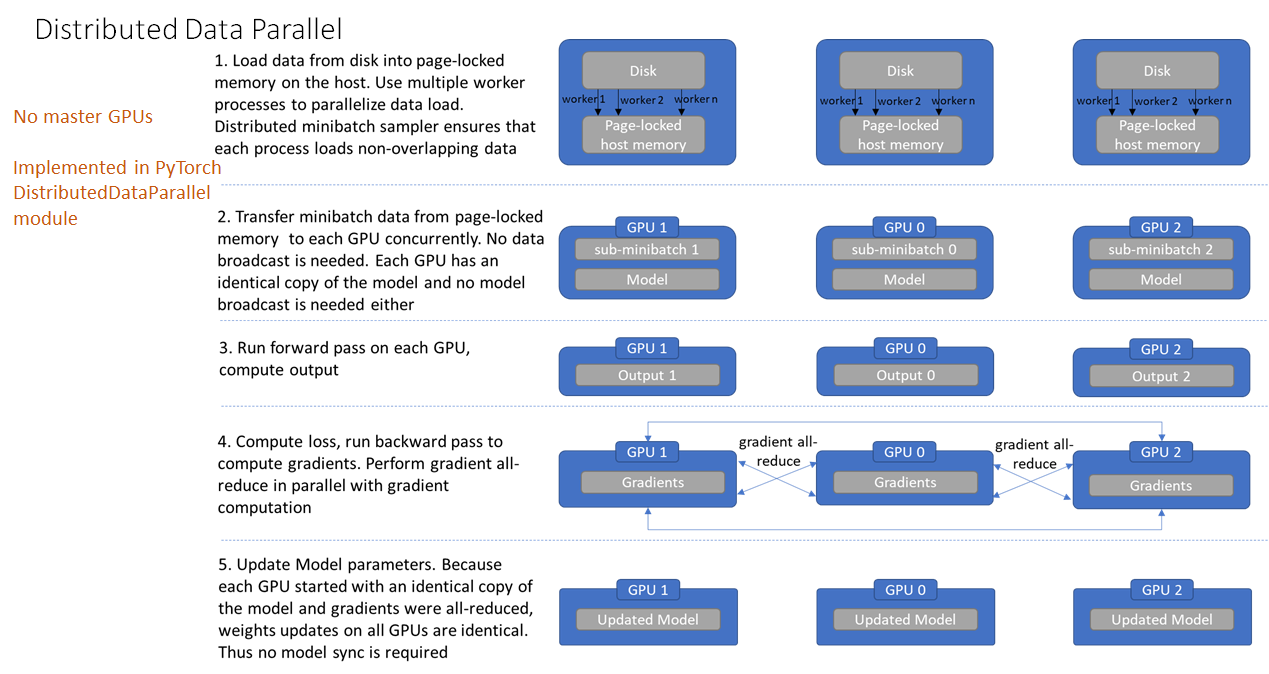
DDP为每个GPU创建一个进程,每个进程对应一个独立的训练过程(多进程,适用单机和多机训练),梯度计算完成后由rank=0的进程broadcast到所有进程,之后各进程用改梯度来独立的更新参数,各进程的模型参数始终保持一致。
1 | import torch |
1 | eg |
c. Hugging Face Accelerate:
1 | Eg |
mutil GPU config
How many different machines will you use (use more than 1 for multi-node training)?
– 在几台机器(物理意义)上训练Should distributed operations be checked while running for errors? This can avoid timeout issues but will be slower. [yes/NO]:
– 启用这个选项可以帮助你避免因为错误导致的超时问题,但可能会降低训练速度
Do you wish to optimize your script with torch dynamo?[yes/NO]:
– Torch Dynamo 是 PyTorch 的一个新特性,用于通过动态跟踪和编译 Python 代码来提升模型的运行效率。如果你希望通过这个工具提高模型训练或推理的速度,可以选择
yes。Do you want to use DeepSpeed? [yes/NO]:
– DeepSpeed 是微软开发的一个深度学习优化库,专门用于高效的分布式训练。它可以显著提高大规模模型的训练速度,减少显存占用,并支持混合精度训练。如果你正在训练一个大型模型并且希望提高训练效率,可以选择
yes。Do you want to use FullyShardedDataParallel? [yes/NO]:
– 选择
yes:如果决定启用 FSDP,PyTorch 会自动在训练中使用 FSDP 进行优化。你可能还需要根据实际情况配置 FSDP 相关的参数。选择
no:如果选择no,则不会启用 FSDP,训练将不会使用这种内存优化策略。Do you want to use Megatron-LM ? [yes/NO]:
选择 yes:如果决定启用 Megatron-LM,你可能需要进行额外的配置和调整来确保其正确集成到你的训练过程。
选择 no:如果选择 no,训练将不会使用 Megatron-LM,通常会依赖于默认的训练设置和策略。
1 | accelerate configuration saved at /home/dell/.cache/huggingface/accelerate/default_config.yaml |
Common Screen Commands
**Introduction:**In project development, when executing programs on the Linux terminal, if the terminal is closed, the program execution will also terminate. This poses significant inconvenience for long-running programs.
Screen facilitates the management of multiple command-line workflows without concern for their interference. Programs are automatically backgrounded and continue execution until completion.
Start a New screen Session
1 | # Start a new screen session named "my_session" |
View Existing screen Sessions
1 | # List all screen sessions |
Attach to an Existing screen Session
1 | # Attach to the screen session named "my_session" |
Detach from an Existing screen Session
1 | # Way 1 |
Delete an Existing screen Session
1 | # Delete the screen session named "my_session" |
Eg
1 | 安装: |
Zip 环境移植
1 | cd 对应的环境envs文件夹 |
Docker使用及封装、dockerfile
1 | E.g (docker命令只在宿主机内有效) |
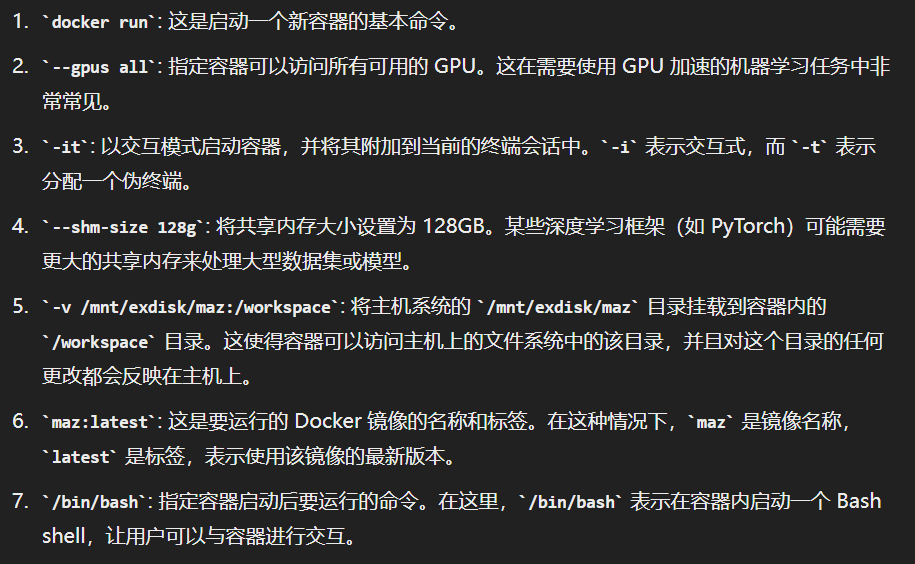
1 | 命令小结 |
LLM & 多模态模型
1 | CLIP->BLIP->BLIPv2->InstructBLIP->LLAVA->MINIGPT4 |
理论基础
Fine-tuning: 在预训练模型(通常在一些大规模的通用数据集上训练,可以视作一个基础模型,能够在广泛任务中发挥作用)基础上,通过进一步训练,使其适应特定任务或领域的过程,微调则是在特定数据集上额外训练,以提高模型在特定任务上的性能。
【大规模语言模型:从理论到实践 (intro-llm.github.io)】
torchkeras—LLM微调
CLIP
- ClIP如何进行预训练:
输入:图片+文字的配对
进入Encoder,生成特征,在特征上作对比学习,特征矩阵里获得正样本和负样本
- 提出了
prompt engineering和prompt ensemble两种方式来提高模型的准确率
– 识别图片机制:用图片给到图片编码器,再去和ImageNet的1000个分类词作相关性匹配,把相关性最大的词挑出来,即完成分类。
- 有趣的应用:
- 生成图
- 物体的分割和检测
- 视频检索(OCR)

Prompt engineering
为什么要做:
- Prompt的多义性
- 预训练时基本都是一个句子,很少是一个单词,可如果做推理的时候,输入只是单词,抽取出来的特征可能就不好
CLIP的解决方案:Prompt template:“A photo of a {label}”
使用了这个template后,准确度提升了1.3%
- CLIP工作最大的贡献,在于打破了固定种类标签的范式。
【CLIP源码解析】
Phi3v
四、Todo-Task
熟悉phi2、phi3的训练代码,在4090上把MIMIC-CXR的对齐跑起来
Captioning评估指标代码(BLEU、ROUGE、F1等等)
测phi3-v在三个数据集的zero-shot精度(EXMatch)
测phi3-v在LLaVA-Med的精度(人类评估、GPT4评估)
建议先试试phi-3v能不能跑(4090不支持flash-attention,可能显存会不够):
1、先把mimic数据整理成PubMed对齐数据一样(参考/data/liangx/Phi-3CookBook/data/)
2、参考/data/liangx/Phi-3CookBook/src/dataset/* 写数据集读取的类
3、改训练代码;
这是Phi3-V的代码:https://github.com/microsoft/Phi-3CookBook/blob/main/code/04.Finetuning/vision_finetuning/finetune_hf_trainer_docvqa.py
文档:https://github.com/microsoft/Phi-3CookBook/blob/main/md/04.Fine-tuning/FineTuning_Vision.md
Phi2的代码:https://github.com/DLYuanGod/TinyGPT-V/tree/main
论文:TinyGPT-V: Efficient Multimodal Large Language Model via Small Backbones
Captioning评估代码可以参考(137行)https://github.com/ecoxial2007/DCG_Enhanced_distilGPT2/blob/main/train_ver4_iu_xray.py
直接用 /data/liangx/Phi-3CookBook/llava-qa_eval_after.json 去试,能输出coco和chexbert几个指标就行
Learning & Planning
https://jiaweihu-xdu.github.io/collaboration/Learning&Planning/

